Online File Caching in Latency-Sensitive Systems with Delayed Hits and Bypassing
Online File Caching in Latency-Sensitive Systems with Delayed Hits and Bypassing
Introduction
在实际应用中,如内容交付网络(CDN)和移动边缘计算(MEC),由于缓存和远程数据中心之间的物理距离长,从远程数据中心拿到cache miss的文件的延迟可能超过100ms,而文件的两个连续请求的平均间隔时间可能低至1μs,例如每秒1M个文件请求。这就导致了一个有趣的情况。在从远程数据中心获取文件期间,无法立即处理对该文件的后续请求,因此不应简单地将其视为cache hit,也不同于简单的cache miss,而应该是Delayed Hit。
此外,传统的缓存模型假设所有miss的文件在被交付给用户之前都必须从远端获取并存储在缓存中,而在与云相关的应用程序场景中,用户的文件请求可以被缓存服务器直接转发到远程并由远程云直接为用户提供文件,我们把这种情况称之为bypass。
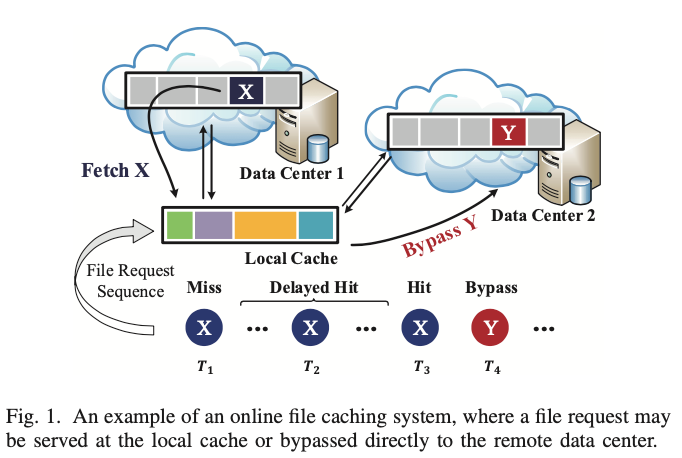
Delayed Hit代表性工作是[6]中研究的paging问题,其中作者新颖地揭示了Delayed Hit在大吞吐量系统中的重要性,并提出了MAD,这是一种在线解决方案,将文件的聚合延迟纳入现有的实用缓存算法,如LRU[10]、ARC[11]和LHD[12]。
paging represents the special case of the caching problem where the size and fetching cost are both uniform for each file. Weighted paging means the uniform file size but non-uniform fetching costs. File caching means non-uniform file sizes and the fetching cost can be uniform or non-uniform. When the size and fetching cost are both non-uniform, we call it the general file caching.
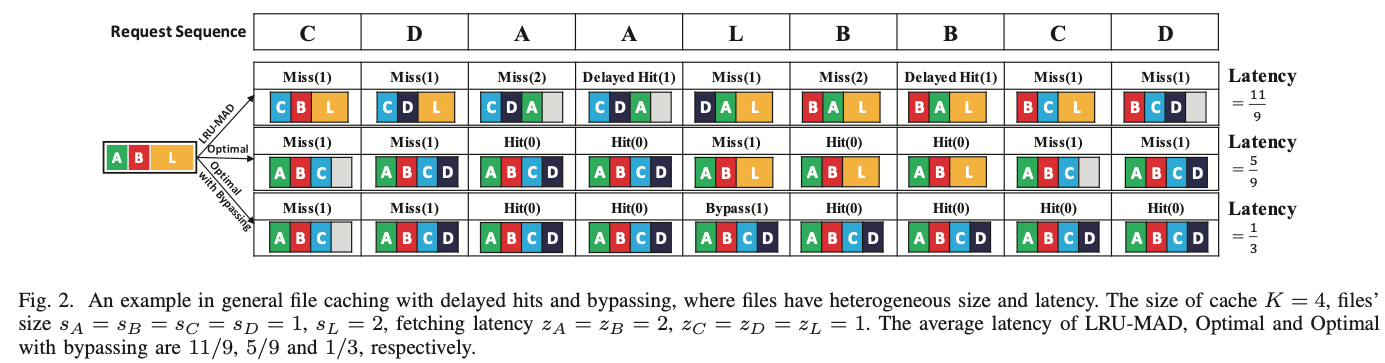
然而,基于云的应用程序中的文件大小差别很大,在谷歌的trace中可能有数千倍。因此,各种文件的获取成本可能会大不相同,因此应该研究general file caching问题。此外,在基于云的系统中,还应考虑bypass。以下示例说明了现有方案无法解决具有delayed hit和bypass的在线通用文件缓存问题。
PROBLEM FORMULATION
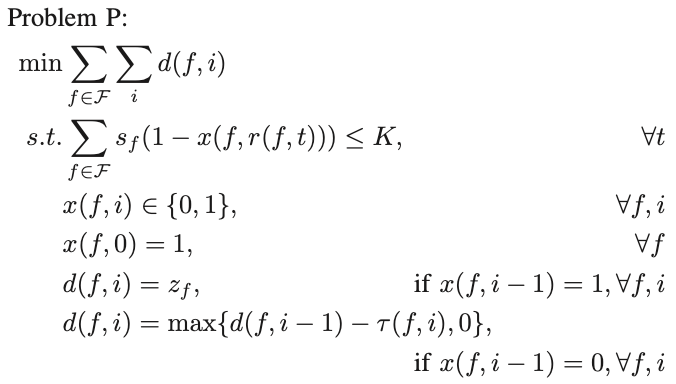
目标:最小化所有请求的延迟
s.t. 1、缓存容量限制 2、决策变量 3、初始化 4、延迟计算
ONLINE ALGORITHM
A. Estimated Weight
这个问题的核心是如何处理delayed hit。在MAD[6]的设计中,他们使用累积延迟来表征由cache miss引起的总延迟。
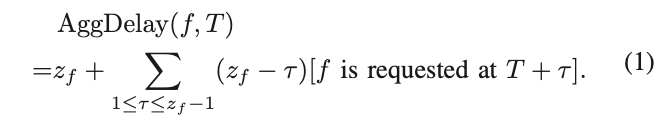
文件f的总延迟在实际中无法直接计算,因为它需要未来信息。MAD使用过去所有f请求的平均累积延迟来估计下一个f请求的累积延迟。然而,这种估计并不准确,因此不能保证MAD的性能。我们在图3中显示了估计值和实际累积延迟之间的差距。
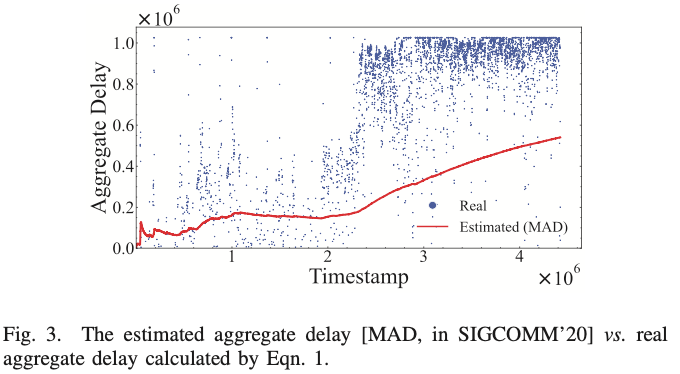
为了避免错误估计的影响,我们使用cache miss引起的累积延迟的上限,即$z_i^2$,来估计cache miss 引起的实际延迟。
虽然使用上限来估计cache miss引起的累积延迟会产生具有性能保证的算法,但这种方法的实际性能可能较差,因为它可能会给一些不经常请求的文件赋予太多权重。通常,预测累积延迟的方法是激进的,而使用上界的方法是保守的。为了在这两种方法之间进行权衡,我们使用以下等式来表示每个文件的权重:

B. CaLa

